Cover photo by James Wainscoat on Unsplash
Note de l'auteur: cet article a pour objectif de partager mon travail sur la conception d'un outil d'optimisation de portefeuille destiné aux utilisateurs travaillant dans le domaine de la gestion de portefeuilles. L'outil est resté au stade "prototype" et n'a jamais fait partie d'aucune démarche commerciale. Il n'est jamais devenu un produit ... et avec un peu recul, je peux dire qu'il était plutôt destinés aux data scientists spécialisés dans la finance qu'aux asset managers. Par ailleurs, je ne suis pas un expert de la finance, je suis un passionné de la Swarm Intelligence. Les explications financières et scientifiques proviennent de sources dont les références bibliographiques sont indiquées à la fin de l'article.
1.1. Contexte scientifique
Le présent projet en Data Science propose une alternative à la méthode appliquée dans l’étude scientifique effectué par Alfaro Cid E. et al., voir référence [ALF], pour la minimisation du risque d’un portefeuille d’actifs financiers. En effet, dans [ALF] on propose une méthode de minimisation de la Value-at-Risk (valeur à risque) avec des algorithmes génétiques (GA). Dans notre étude, nous proposons une version modifiée d’un autre algorithme, également issu du domaine de la Swarm Intelligence (intelligence de l’essaim), appelé Particle Swarm Optimization (PSO) ou optimisation par essaims particulaires (OEP).
Nous essayons dans ce projet de démontrer que les portefeuilles (ou solutions) trouvés par PSO sont plus efficaces que ceux trouvés par GA vis-à-vis des solutions trouvées par une méthode classique de minimisation du risque. Pour ce faire, nous avons influencé le comportement standard de l’algorithme.
Par ailleurs, un outil permettant de générer les solutions de chaque algorithme sur une longue période, comprenant plusieurs tendances du marché, a été développé. L’outil permet ensuite d’appliquer les solutions trouvées à des scénarios correspondants à une tendance spécifique (soit une hausse soit une baisse) et ultérieure dans le temps et par conséquent, de valider l’efficacité des portefeuilles trouvés. Finalement, l’unexpected loss (ou perte inattendue) est calculée, c’est un indicateur essentiel qui permet de maîtriser le coût en capital exigé par les régulateurs.
Malgré l’existence d’outils permettant de calculer la VaR, ceux qui permettent de la minimiser sont inexistants sur l’Internet. Nous pensons que ce type de solution devrait peut-être exister dans le cercle très fermé des éditeurs logiciels financiers avec des développements customisés, cependant nous n’avons pas de connaissance à l’heure actuelle sur les méthodes et les types d’optimisation proposés par ces solutions.
La Value-at-Risk (VaR) est un indicateur très utilisé en gestion de risques financiers. Elle permet de mesurer un niveau de perte inattendue qui peut être dépassée à un horizon de temps donnée avec une probabilité donnée. Elle est fondamentale pour les investisseurs en bourse, les asset managers et également pour les banques et les assurances qui doivent couvrir leurs pertes inattendues par du capital (réglementation Bale, Solvency).
Minimiser la VaR est un « problème difficile » (terme définie dans [CLE]), en effet, la VaR est une fonction non convexe et non différentiable, par conséquent sa minimisation ne peut s’effectuer avec des méthodes classiques d’optimisation telles que la descente du gradient. Les algorithmes issus de la Swarm Intelligence s’adaptent bien à ce genre de « problèmes difficiles ».
L’optimisation appliquée est en réalité une optimisation multi-critère car non seulement on essaie de minimiser la VaR mais on cherche également à maximiser le rendement ou gain de portefeuilles d’actifs financiers.
1.1.1. Enjeux
Une minimisation judicieuse de la VaR permet de maitriser le coût en capital exigé par les régulateurs.
Des adaptations innovantes des algorithmes issus de la swarm intelligence permettent de réaliser de telles optimisations de la VaR.
Concevoir une nouvelle démarche pour les acteurs du domaine financier leur permettant d’intégrer simultanément les solutions trouvées par plusieurs méthodes (classiques et issues de la Swarm Intelligence) et d’effectuer un choix de la meilleure solution.
1.2. Etat de l’art existant et disponible au début des travaux
1.2.1. Notion de « problème difficile »
Selon [CLE], « la difficulté d’un problème d’optimisation dans un espace de recherche donnée est la probabilité de ne pas trouver une solution en choisissant une position au hasard selon une distribution uniforme. C’est donc la probabilité d’échec au premier essai. »
Ci-dessous trois exemples extraits d’un jeu d’essai classique pour les problèmes d’optimisation. Ce sont des fonctions possédant un espace de recherche à deux dimensions (axes x1 et x2).
 Figure 1 Deux problèmes difficiles (Tripod et Alpine) et un problème convexe (Parabole)
Figure 1 Deux problèmes difficiles (Tripod et Alpine) et un problème convexe (Parabole)
Le problème « Tripod » déroute de nombreux algorithmes qui se sont facilement piéger dans l’un ou l’autre des deux minimums locaux. Il présente des discontinuités brutales ce qui ne gêne en rien le PSO. La « Parabole » présente un seul minimum, de par son caractère stochastique, le PSO ne pourra pas être aussi efficace qu’un algorithme déterministe, tel que la descente du gradient.
L’objectif de ce sous-chapitre est de rappeler que la minimisation du VaR est un « problème difficile » pour lequel les algorithmes de la Swarm Intelligence sont plus adaptés que les algorithmes classiques tels que la programmation quadratique (QP).
1.2.2. Gestion de portefeuille : Le modèle de Markowitz
Le modèle de Markowitz fait la double hypothèse que :
- Les marchés d'actifs financiers sont efficients.
- C'est l'hypothèse d'efficience du marché selon laquelle les prix et rendements des actifs sont censés refléter, de façon objective, toutes les informations disponibles concernant ces actifs.
- Les investisseurs ont de l'aversion envers le risque.
Ils ne seront prêts à prendre plus de risques qu'en échange d'un rendement plus élevé.
À l'inverse, un investisseur qui souhaite améliorer la rentabilité de son portefeuille doit accepter de prendre plus de risques.
L'équilibre risque/rendement jugé optimal dépend de la tolérance au risque de chaque investisseur.
1.2.3. Rendement et Volatilité d’un Portefeuille
On suppose généralement que la préférence de l'investisseur pour un couple risque / rendement peut être décrite par une fonction d'utilité quadratique. De plus, les évolutions du marché sont supposées suivre une distribution symétrique de Pareto.
Par conséquent, seuls le rendement attendu (l'espérance de gain) et la volatilité (l'écart type) sont les paramètres examinés par l'investisseur. Ce dernier ne tient pas compte des autres caractéristiques de la distribution des gains, comme son asymétrie ou même le niveau de fortune investi.
Le rendement d'un portefeuille est une combinaison linéaire de celui des actifs qui le composent, pondérés par leur poids ωi dans le portefeuille. Placé dans un univers incertain, l’investisseur ne peut pas calculer d’avance la rentabilité, car la valeur du titre en fin de période est aléatoire, ainsi que dans certain cas, la rémunération perçue durant la période. L’investisseur utilise alors, un rendement attendu qui est la moyenne des rendements possibles pondérés par leur possibilité de réalisation.
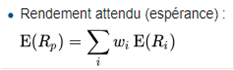
La volatilité du portefeuille (constatez le symbole grec « Sigma », ci-dessus) est une fonction de la corrélation entre les actifs qui le composent. Cette fonction n'est pas linéaire.
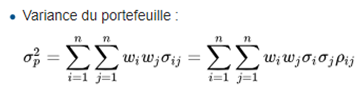
1.2.4. Les portefeuilles Sigma-efficient
Le portefeuille de variance minimale (Minimum Variance Portfolio) est le portefeuille efficient avec le risque « Volatilité » minimale, explications [CAP] :
En supposant un grand nombre d'actifs financiers et toutes les combinaisons possibles, il est donc possible de calculer l'espérance et la variance du rendement prévisionnel d'un très grand nombre de portefeuilles.
Chaque portefeuille aura donc des caractéristiques d'espérance et de variance différentes, en fonction du choix des actifs, des pondérations et des corrélations entre les actifs.
Il est alors possible d'obtenir un graphique représentant le risque et le rendement de chaque portefeuille, et de déterminer une frontière d'efficience à partir des portefeuilles dominants/dominés.
Chaque point sur la courbe bleue à partir du point rouge "Portefeuille à variance minimale" correspond à un portefeuille efficient ; c'est ce que l'on appelle la frontière d'efficience ou frontière de Markowitz.
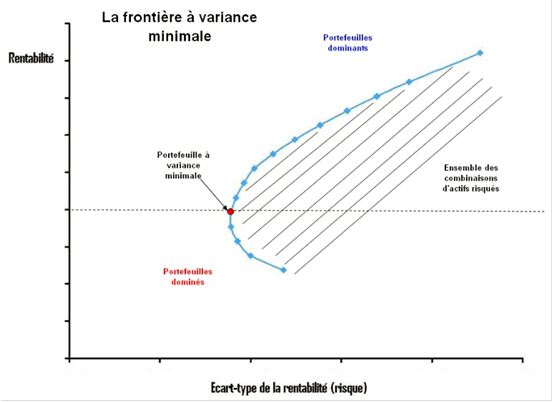
Figure 3 Graphique illustrant une frontière efficiente et la solution (en rouge) représentant le portefeuille ou solution à variance minimale.
Si un portefeuille se trouve dans la zone hachurée, il n'est pas efficient car il existe (1) un autre portefeuille apportant ce même niveau de rendement mais avec un risque plus faible ou (2) un autre portefeuille apportant un rendement supérieur pour le niveau de risque considéré.
Chaque investisseur peut ensuite choisir n'importe quel portefeuille sur le demi-courbe bleue, en fonction du niveau de risque qu'il est prêt à supporter ou bien du rendement qu'il espère (maximisation de l'utilité de l'investisseur).
1.2.5. Les limites du modèle de Markowitz
Avec les ajustements récents, ce modèle s’est trouvé plusieurs limites soulevées par plusieurs praticiens de la théorie financière. Parmi ces limites, on note :
Le modèle suppose la rationalité des investisseurs. Or, la réalité a prouvé qu’une croyance tout à fait irrationnelle peut être vu légitime par le seul fait qu’elle soit collectivement admise par un opérateur crédible ;
Le modèle ne s’est pas intéressé à la décomposition du risque global du marché mais s’est limité à l’analyse et à l’évaluation du risque individuel ou spécifique ; d’où l’apparition d’un nouveau modèle d’évaluation des actifs financiers (MEDAF) ;
Le modèle suppose également la normalité de la distribution des rentabilités, chose qui n’est pas toujours vérifiable dans la réalité. Cette limite a été résolue par l’apparition du modèle de « Dominance stochastique » qui s’applique à tout type de distribution ;
La variance a été considérée comme une mesure simplificatrice de la fonction de la rentabilité, tandis que la « Dominance stochastique » admet une comparaison de la distribution entière ;
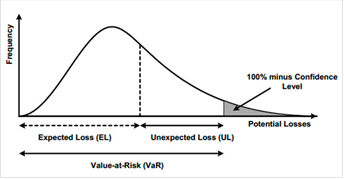
La variance étant une mesure non parfaite du risque, une nouvelle technique de mesure a été développée en 1993, appelé Value-At-Risk (VaR). Cette technique permet de déterminer la perte maximale probabilisée sur un portefeuille quelconque.
1.2.6. La Value-At-Risk (Valeur à risque)
La VaR est une notion utilisée généralement pour mesurer le risque de marché d'un portefeuille d'instruments financiers. Elle correspond au montant de pertes qui ne devrait être dépassé qu'avec une probabilité donnée sur un horizon temporel donné.
L'utilisation de la VaR n'est désormais plus limitée aux instruments financiers : on peut en faire un outil de gestion des risques dans tous les domaines.
La VaR est définie par rapport à un horizon de temps T et le seuil de confiance α (on parle par exemple de VaR 10 jours 95%).
La VaR T jours à une confiance α peut être définie (de manière équivalente) comme :
La pire des pertes pouvant être constatée en T jours dans les α = 95% de cas les plus favorables
La moindre perte pouvant être constatée en T jours dans les 1-α = 5% de cas les moins favorables
Le montant au-delà duquel une perte survient en T jours avec une probabilité de 1-α = 5%
1.2.7. La VaR et les pertes inattendues
La VaR est un indicateur essentiel pour les régulateurs, en effet elle permet de maitriser le coût en capital exigé par ces derniers.
Basel II Operational Risk, AMA Quantitative Standards 669(b) : « Les autorités de contrôle demanderont à la banque de calculer ses exigences de fonds propres réglementaires en faisant la somme de la perte attendue (EL) et de la perte inattendue (UL), à moins que la banque ne puisse démontrer qu’elle intègre adéquatement le niveau de solvabilité dans ses pratiques commerciales internes. Autrement dit, pour fonder l'exigence de fonds propres réglementaire minimale sur UL uniquement, la banque doit être en mesure de démontrer, à la satisfaction de son autorité de contrôle nationale, qu'elle a mesuré et comptabilisé son exposition à l’EL ».
1.2.8. Notre approche par rapport aux études existantes
La référence principale est l’étude de l’équipe d’Alfaro Cid E. et al., « Minimizing Value-at-Risk in a portfolio optimization problem using a multiobjective genetic algorithm (GA) » [ALF]. Cette étude nous a servie de base pour la définition de la démarche et les objectifs à atteindre dans ce projet. Ce qui nous différencie de cette étude est l’utilisation d’un autre algorithme d’optimisation multi-critère issu également de la Swarm Intelligence, à savoir le multiobjective PSO (MOPSO).
L’étude de Yourdkhani S., « Portfolio Management by using Value-at-Risk (VaR) - A Comparison between Particle Swarm Optimization and Genetic Algorithms » [YOU], montre en effet une comparaison entre PSO et GA. Cependant, l’optimisation appliquée est monocritère (absence de maximisation de la rentabilité) et la comparaison est effectuée en termes de performances (rapidité et robustesse de l’algorithme). Ce qui nous différencie de cette étude est l’utilisation d’un algorithme d’optimisation multicritère et une comparaison en termes de l’efficacité des portefeuilles (solutions) ; nous proposons donc un comparatif lié au cas d’usage métier.
Nous souhaitons effectués un comparatif entre nos résultats et ceux de l’étude [ALF].
Le comparatif sera basé sur l’écart d’efficacité (ou erreur de substitution), définit dans [ALF], entre les portefeuilles VaR-efficient trouvés par les algorithmes de Swarm Intelligence (NSGA II et MOPSO, voir chapitre 3) et les portefeuilles Sigma-efficient trouvés par la méthode classique (programmation quadratique.
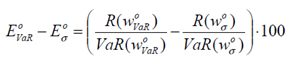
Il y a plusieurs niveaux d’écart d’efficacité :
Nous cherchons à connaître la proportion de portefeuilles VaR-efficient qui se trouvent dans chaque écart défini ci-dessus.
D’autres indicateurs de performances sont utilisés : on calcule les différences (ou erreurs) entre les valeurs VaR des portefeuilles VaR-efficient et des portefeuilles Sigma-efficient :
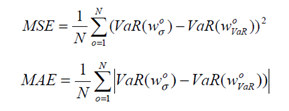
- Données In-samples, voir chapitre 1.5.2.2.3; l’objectif est de montrer qu’il existe un écart d’efficacité important en faveur des solutions trouvées par les algorithmes de la Swarm Intelligence (NSGA II et MOPSO) par rapport à celles de la méthode classique (programmation quadratique, QP). Ci-dessous les résultats obtenus par l’étude [ALF] :
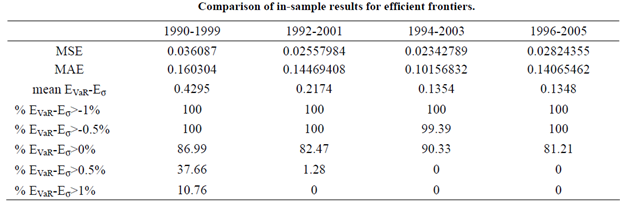 Tableau 1 Résultats de l'équipe [ALF], comparatif NSGA-II vs QP pour les périodes à plusieurs tendances (in-samples)
Tableau 1 Résultats de l'équipe [ALF], comparatif NSGA-II vs QP pour les périodes à plusieurs tendances (in-samples)
- Données Out-samples, voir chapitre 1.5.2.2.3 ; l’objectif est de tester les solutions trouvées dans le scénario précédents sur les valeurs d’actifs financiers correspondantes à des périodes spécifiques, de baisse ou de hausse, différentes et ultérieures à celles des données in-samples. On cherche à constater si cet écart d’efficacité en faveur des solutions trouvées par les algorithmes de la Swarm Intelligence (NSGA II et MOPSO) a pu être conservé. Ci-dessous les résultats obtenus par l’étude [ALF] :
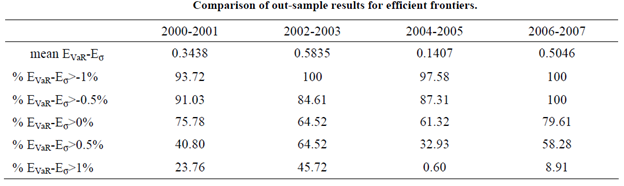 Tableau 2 Résultats de l'équipe [ALF], comparatif NSGA-II vs QP pour les périodes à tendance unique (out-sample)
Tableau 2 Résultats de l'équipe [ALF], comparatif NSGA-II vs QP pour les périodes à tendance unique (out-sample)
 Figure 2 Les quatre périodes in-sample avec les période out-sample correspondantes
Figure 2 Les quatre périodes in-sample avec les période out-sample correspondantes
Finalement, nous comparons les écarts entre NSGA II et MOPSO en espérant montrer que la proportion des portefeuilles VaR-efficient trouvés par MOPSO par rapport à QP dans chaque niveau d’écart d’efficacité est plus importante que celle trouvée pour NSGA II par rapport à QP dans [ALF].
1.3.1. Algorithmes génétiques (AG ou GA)
Les algorithmes génétiques (Genetic Algorithms) tentent d’imiter informatiquement les procédés par lesquels la sélection naturelle opère, et de les appliquer pour résoudre divers problèmes, en entreprise ou dans le cadre de la recherche [LAR].
Ils fournissent un cadre pour étudier les effets de facteurs inspirés de la biologie, comme la sélection d’un compagnon, la reproduction, la mutation et le recouvrement d’information génétique.
Dans le monde des GA, la qualité des différentes solutions est comparée et les meilleures solutions potentielles évoluent pour produire des solutions plus optimales encore.
1.3.1.1. Non-dominated Sorting Genetic Algorithm-II (NSGA II)
De manière générale, les algorithmes évolutionnistes multi-objectif affectent un score à une solution selon qu’elle est dominée ou non par d’autres solutions de la population courante et éventuellement si elle domine d’autres solutions. Un exemple classique est NSGA II. Cet algorithme génétique utilise une méthode de ranking qui attribue aux solutions non-dominées (voir Annexe) de la population courante le meilleur score. Puis les solutions, qui ne sont dominées que par les solutions potentiellement efficaces, reçoivent le second meilleur score et ainsi de suite.
De cette manière, la population est organisée en couches où chaque couche contient des solutions non comparables entre elles
1.3.2. Algorithmes d’optimisation par essaims particulaires (OEP ou PSO)
Le modèle de base de l’optimisation par essaims particulaires (Particle Swarm Optimization) est défini de façon informelle en s’inspirant des échanges d’informations entre abeilles d’une ruche. Un fois qu’un bon site a été localisé par une abeille ouvrière, il est rapidement et efficacement exploité par d’autres [CLE].
Chaque particule (donc abeille) combine linéairement 3 éléments pour décider de son prochain déplacement :
1.3.2.1. Multi-objective PSO (MOPSO)
Le Multi-objective PSO est la version multi-critère de PSO. Comme expliqué dans 3.1.1.1, cet algorithme se base également sur la notion de « domination » entre les solutions. On appelle « archive » (applicable également à NSGA II) l’ensemble de solutions non-dominées (voir Annexe) à un moment ou itération (ou génération) donnée lors de l’exécution de l’algorithme.
Il existe plusieurs méthodes pour la détermination de la non-dominance :
Le calcul de la sigma-distance, voir [MOS]. C’est la méthode applicable à ce projet.
Le calcul de la Enhanced Є-dominance, voir [HAO] et [MOS2]
1.4. Incertitudes techniques et scientifiques, verrous technologiques et problèmes à résoudre
1.4.1. Volumétrie
La volumétrie des données appliquée à ce projet est déterminée par la profondeur temporelle de la période in-sample, ici 10 ans. La volumétrie correspondante à une profondeur de 10 ans pour les 12 indices boursiers utilisés pouvait très bien être gérée sur un seul ordinateur portable avec une configuration de 16Go de mémoire vive et un processeur Intel i5.
Cependant, pour l’industrialisation d’une telle solution, il faut apporter un maximum de flexibilité dans la sélection du nombre d’indices et de profondeur temporelle de données lors de l’exécution des différents algorithmes d’optimisation. Par conséquent, nous avons intégré à notre solution un design de calcul distribué dans un environnement Big Data, illustré ci-dessous.
Le développement et l’implémentation du calcul distribué de l’algorithme MOPSO reste un « next step » dans la roadmap de notre outil.
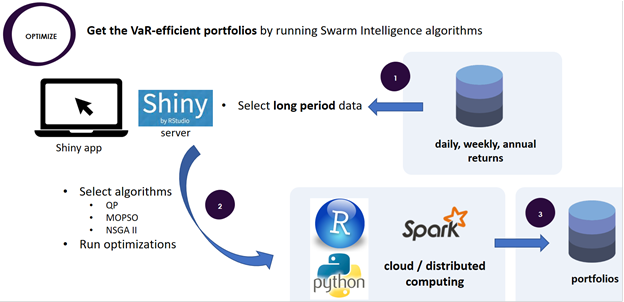 Figure 10 Design macro pour le calcul distribué dans un environnement Big Data
Figure 10 Design macro pour le calcul distribué dans un environnement Big Data
1.5. Travaux effectués
1.5.1. Projet Agile
Nous considérons que la psychologie du data scientist ne doit pas se calquer sur la psychologie type d’un développeur efficace ou d’un créateur de startup. Par conséquent, la méthode Agile, ici Scrum, a été adaptée à une démarche Data Science, donc aux cycles de réflexion R&D des data scientists.
L’équipe est composée d’un data scientist expérimenté, également Scrum Master, et de trois data scientists junior. Chaque data scientist est responsable d’un algorithme (NSGA-II et MOPSO).
L’environnement technique de développement Data Science a été défini selon les compétences de chaque data scientist en langage R (environnement RStudio) ou en langage Python (environnement Jupyter notebook). L’interface graphique permettant de visualiser et de partager les résultats du benchmark a été développée avec le langage R Shiny
1.5.2. La démarche projet
1.5.2.1. Equipe et rôles
L’équipe est composée d’un data scientist expérimenté, également Scrum Master, et de trois data scientists junior. Chaque data scientist est responsable d’un algorithme (NSGA-II et MOPSO). Un responsable Financial Services de l’entreprise a été désigné comme Product Owner du projet.
En plus des objectifs expliqués dans l’introduction du présent document, nous considérons que la montée en compétences des data scientists junior est primordial pour le succès de l’activité. Par conséquent, les data scientists ont été assisté par le data scientist senior afin de comprendre « la philosophie », ainsi que les avantages et les inconvénients de l’algorithme dont il ou elle avait la responsabilité.
Chaque data scientist était responsable du choix et de l’utilisation d’une librairie spécifique pour exécuter l’algorithme ainsi que de la documentation associée à son travail.
A la fin de chaque itération (sprint) le data scientist junior doit fournir au data scientist senior les résultats des différents scénarios d’optimisation effectués avec les librairies. Le data scientist senior était chargé de collecter les résultats et de les intégrer à l’outil destiné aux asset managers (développé également par le data scientist senior).
Après constatation des limites (manque de flexibilité) des librairies utilisées par les data scientists junor, le data scientist senior décide de prendre en charge le développement de la modification du comportement standard de l’algorithme MOPSO.
1.5.2.2. Démarche Data Science
La démarche data science comprends plusieurs étapes et elle s’exécute de manière itérative, au sein d’un même sprint on peut effectuer soit une partie soit la totalité des étapes, tout dépend de la complexité du problème.
Les étapes de la démarche data science sont les suivantes et elles sont décrites ci-après :
Les trois étapes précédentes ont été implémentées dans un environnement de programmation en langage R (RStudio).
La visualisation n’est pas une étape de la démarche data science, cependant elle est nécessaire pour le partage des résultats intermédiaires obtenus. L’interface graphique permettant de visualiser et de partager les résultats a été développée avec le langage R Shiny
1.5.2.2.1 Environnent Data Science
o Langage : R version 3.4.4
o IDE : RStudio 1.1.453
o Visualisation : RStudio Shiny
Principaux packages utilisés
o Collecte de données : package quantmod
o Traitement des séries temporelles : package timeSeries
o Calcul de la VaR, de la rentabilité et de la Frontière Efficiente avec méthode classique (programmation quadratique) : package fPortfolio
1.5.2.2.2 Collecte de données
Valeurs journalières ajustées (adjusted daily returns) de 12 indices boursiers entre 1990 et 2007 :
- USA DJ Industrial (DJI)
- USA SP500 (GSPC)
- USA Nasdaq (IXIC)
- Canada SPTSX (GSPTSE)
- UK Footsie (FTSE)
- France CAC 40 (FCHI)
- Germany DAX (GDAXI)
- Spain IBEX 35 (IBEX)
- Holland AEX (AEX)
- Sweden OMX (OMX)
- Japan Nikkei 225 (N225)
- Europe Euro Stoxx 50 (STOXX50E)
Source (publique) : Yahoo ! Finance.
Collecte des données avec le package R quantmod.
1.5.2.2.3 Qualité de la donnée
Pour la période 1990-1993, trois indices boursiers présentaient une quantité importante de valeurs manquantes. L’équipe a décidé de supprimer toutes les « lignes » présentant des valeurs manquantes, par conséquent les valeurs des indices possédant des valeurs à ces dates ont été également supprimées afin de garder des données sans valeurs manquantes. Par conséquent les dates des valeurs de référence des 12 indices boursiers commencent à partir du mois de mars 1993 (au lieu de janvier 1990).
Préparation des données
Les packages R quantmod et timeSeries ont été utilisés afin d’obtenir les huit 8 datasets suivants (voir chapitre 1.3 pour rappel des objectifs des datasets) composés des valeurs hebdomadaires ajustées des 12 indices boursiers :
In-samples (échantillons d’entrée) : périodes de 10 comprenant plusieurs tendances :
- In-sample 1990-1999
- In-sample 1992-2001
- In-sample 1994-2003
- In-sample 1996-2005
Out-samples (échantillons de sortie) : période de 2 ans comprenant une seule tendance, ces données permettent de valider les portefeuilles (solutions) trouvées avec les In-samples :
- Out-sample 2000-2001
- Out-sample 2002-2003
- Out-sample 2004-2005
- Out-sample 2006-2007
1.5.2.2.4 Modélisation et optimisation
Le code écrit en langage R de l’algorithme MOPSO est une adaptation souhaitée et innovante de plusieurs spécifications PSO et MOPSO :
- La référence [CLE] apporte un paramétrage en termes des valeurs conseillées de la taille de l’essaim, de la confiance en soi, de la confiance en les autres et du confinement de l’espace de recherche.
Paramètre MOPSO Valeurs conseillées
Confiance en soi (ω) 0.689343
Confiance en les autres (Cmax) 1.42694
Taille de l’essaim (N) 300
Nombre de générations (EXEC) 100
- La référence [MOS] apporte le pseudo-code général de la MOPSO, du calcul de la sigma-distance et le nombre de générations conseillé (ou nombre d’exécutions). Ci-dessous le pseudo-code, général de la MOPSO.

Par conséquent, nous avons influencé le comportement standard de l’algorithme, par rapport à celui disponible dans les packages les plus connus, tels que DEAP (Python), en effectuant un développement qui intègre ce que nous considérons comme les meilleurs atouts du PSO mono-critère et multi-critère. A notre connaissance, cette approche n’a jamais été tentée.
Fonctions à optimiser
On cherche à maximiser la rentabilité et à minimiser la VaR du portfolio. On utilise des fonctions existantes dans le package fPortfolio. En effet, ce dernier sera utilisé pour l’optimisation des portfolios Sigma-effcient utilisant la méthode classique (programmation quadratique), ainsi le comparatif des résultats sera fiable.
Le calcul de la rentabilité du portfolio est effectué en prenant la moyenne du résultat de la fonction fPortfolio::pfolioReturn(timeSeries, weights).
Le calcul de la VaR du portfolio est effectué avec la fonction fPortfolio::pfolioVaR(timeSeries, weights, alpha).
Avec
*timeSeries *: les valeurs hebdomadaires des indices (soit in-sample ou out-sample) sous format de series temporelles.
*weights *: c’est le portfolio (ou possible solution en question ou position d’une particule).
*alpha *: c’est la confiance correspondante à la VaR, fixée à 95%
1.5.3. Données In-samples : Efficacité des portefeuilles VaR-efficient
Les résultats expliqués dans ce chapitre permettent de montrer le bien fondé de notre démarche scientifique. En effet, avant d’appliquer nos solutions (portefeuilles trouvés par MOPSO) sur des périodes à tendance unique, on chercher à effectuer le même type de comparatif « MOPSO vs Programmation Quadratique (QP) » que celui effectué par [ALF] dans le cas de NSGA-II.
1.5.4. Procédure
L’écart d’efficacité (ou erreur de substitution) définie au chapitre 1.3 a été calculé de la façon suivante :
A partir des portefeuilles trouvés par MOPSO, on calcule pour chaque valeur Return du couple (Return, VaR) correspondant, la VaR avec la fonction fPortfolio::efficientPortfolio(timeSeries, spec, constraints) où le paramètre spec inclut la définition de la valeur Return cible (avec setTargetReturn) égale à celle de MOPSO.
Ainsi on obtient pour la programmation quadratique (QP) le même nombre de portefeuilles que pour MOPSO et par conséquent, on peut effectuer une comparaison fiable des résultats.
1.5.5. Les graphes des résultats
La légende suivante s’applique aux quatre figures ci-dessous :
A gauche : portefeuilles VaR-efficient trouvés par l’équipe [ALF] avec NSGA II vs. portefeuilles Sigma-efficient
A droite : portefeuilles VaR-efficient trouvés avec MOPSO vs. portefeuilles Sigma-efficient
1.5.6. Données In-samples 1990 – 1999
MOPSO a généré 12 solutions ou portefeuilles VaR-efficient.
La figure ci-dessous montre que l’efficacité des portefeuilles VaR-efficient trouvés par MOPSO est supérieure à celle de NSGA II, vis-a-vis des portefeuilles Sigma-efficient respectifs.
La proportion des portefeuilles VaR-efficient de MOPSO est de 100% pour tous les niveaux d’écart d’efficacité (ou erreur de substitution) définis dans le chapitre 1.3.
Les erreurs MSE, MAE et de substitution restent assez importantes : à 0.2%, 0.4% et 0.3% respectivement.
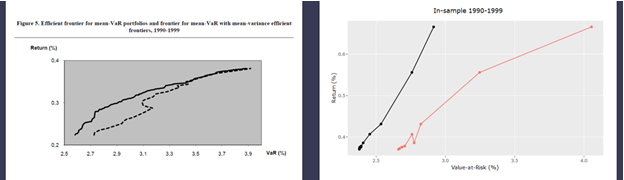 Figure 4 Résultats in-sample 1990-1999
Figure 4 Résultats in-sample 1990-1999
1.5.7. Données In-samples 1992 – 2001
MOPSO a généré 20 solutions ou portefeuilles VaR-efficient.
La figure ci-dessous montre que l’efficacité des portefeuilles VaR-efficient trouvés par MOPSO est supérieure à celle de NSGA II, vis-à-vis des portefeuilles Sigma-efficient respectifs.
La proportion des portefeuilles VaR-efficient de MOPSO est de 100% pour les 3 premiers niveaux d’écart d’efficacité (ou erreur de substitution) définis dans le chapitre 1.3 et de 45% et 20% pour les écarts supérieurs à 0.5% et à 1% respectivement.
Les erreurs MAE et de substitution sont assez importantes : 0.3% et 0.7% respectivement. Le MSE est à 0.096%.
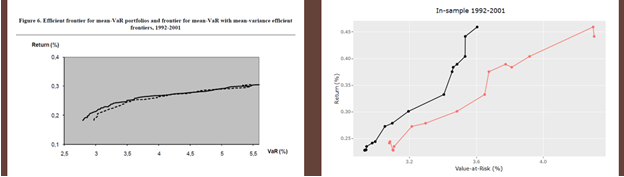 Figure 5 Résultats in-sample 1992-2001
Figure 5 Résultats in-sample 1992-2001
1.5.8. Données In-samples 1994 – 2003
MOPSO a généré 23 solutions ou portefeuilles VaR-efficient.
La figure ci-dessous montre que l’efficacité des portefeuilles VaR-efficient trouvés par MOPSO est inférieure à celle de NSGA II, vis-à-vis des portefeuilles Sigma-efficient respectifs. C’est le seul scénario montrant ce cas. Une analyse est toujours en cours afin d’expliquer ce phénomène.
La proportion des portefeuilles VaR-efficient de MOPSO est de 100% pour les 2 premiers niveaux d’écart d’efficacité (ou erreur de substitution) définis dans le chapitre 1.3 et de 9%, 0% et 0% pour les écarts supérieurs à 0%, à 0.5% et à 1% respectivement. Le résultat est en effet très décevant.
Les erreurs MAE, MSE et de substitution sont malgré tout proches de 0% : 0.004%, 0.058% et -0.092%% respectivement
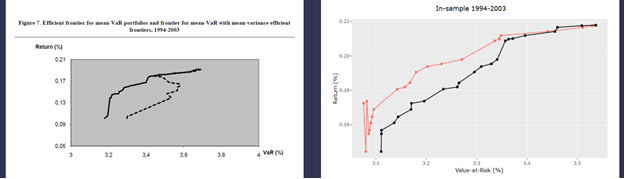 Figure 6 Résultats in-sample 1994-2003
Figure 6 Résultats in-sample 1994-2003
1.5.9. Données In-samples 1996 – 2005
MOPSO a généré 16 solutions ou portefeuilles VaR-efficient.
La figure ci-dessous montre que l’efficacité des portefeuilles VaR-efficient trouvés par MOPSO est supérieure à celle de NSGA II, vis-à-vis des portefeuilles Sigma-efficient respectifs.
La proportion des portefeuilles VaR-efficient de MOPSO est de 100% pour les 2 premiers niveaux d’écart d’efficacité (ou erreur de substitution) définis dans le chapitre 1.3 et de 69%, 13%, 6% pour les écarts supérieurs à 0%, à 0.5% et à 1% respectivement.
Les erreurs MAE, MSE et de substitution sont correctes : 0.06%, 0.17% et 0.23% %% respectivement.
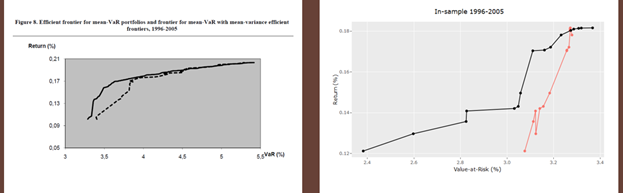 Figure 7 Résultats in-sample 1996-2005
Figure 7 Résultats in-sample 1996-2005
1.5.10. Résumé des résultats
Ci-dessous le résumé des résultats obtenus pour les portefeuilles VaR-efficient trouvés avec MOPSO vis-à-vis des portefeuilles Sigma-efficient obtenus avec la programmation quadratique.
 Tableau 3 Résultats in-sample "MOPSO vs QP"
Tableau 3 Résultats in-sample "MOPSO vs QP"
On peut constater que la proportion des portefeuilles VaR-efficient dont l’écart est supérieur à 0% par rapport aux portefeuilles Sigma-efficient et de 100%, 100%, 9% et 69% pour chaque ensemble de données in-sample respectivement.
Seule l’application des portefeuilles VaR-efficient sur les données in-sample 1994-2003 ont montré des résultats décevants avec seulement 9% des solutions à > 0%, ce qui est très loin d’une majorité de portefeuilles MOPSO.
1.5.11. Données Out-samples : Validation des portefeuilles VaR-efficient
Ci-dessous le résumé des résultats obtenus en appliquant les portefeuilles VaR-efficient de MOPSO (solutions in-samples) aux données out-samples ou périodes à tendance unique.
 Tableau 4 Résultats out-sample "MOPSO vs QP
Tableau 4 Résultats out-sample "MOPSO vs QP
1.5.12. Fonctionnalités
L’outil, développé avec RStudio Shiny, permet aux asset managers de
Collecter et stocker avec une fréquence journalière le cours des indices boursiers à partir des sources publiques (actuellement Yahoo ! Finance). Calculer les rendements journaliers, hebdomadaires et annuels
Obtenir les portefeuilles optimisés avec des algorithmes « classiques » et ceux issus de la Swarm Intelligence (actuellement MOPSO).
Appliquer les portefeuilles sur des périodes à tendance unique et effectuer un comparatif « Swarm Intelligence (actuellement MOPSO) vs QP » avec des indicateurs d’efficacité VaR-efficiency.
Sélectionner la meilleure solution, en calculant les VaR et la perte inattendue (UL) selon le rendement désiré et comparer les résultats des différents algorithmes.
 Figure 8 Fonctionnalités de l'outil destiné aux asset managers
Figure 8 Fonctionnalités de l'outil destiné aux asset managers
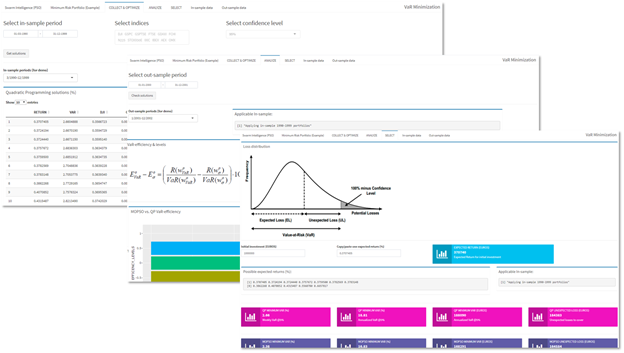 Figure 9 Prises d'écran correspondantes à chaque fonctionnalité de l’outil
Figure 9 Prises d'écran correspondantes à chaque fonctionnalité de l’outil
1.6. Réussites techniques, indicateurs de R&D
1.6.1. Acquisition de connaissances
Au moment de l’écriture de ce rapport, nous n’avons aucune connaissance d’outils ou de logiciels sur le marché permettant d’automatiser les tâches (1) calcul des portefeuilles avec différents algorithmes, (2) applications des solutions sur des périodes à une tendance, (3) comparatif des portefeuilles et (4) calcul de la VaR minimale et la perte inattendue (unexpected loss, UL).
1.6.2. Démarche réussie
Nous avons réussi à appliquer le même niveau de rigueur de la démarche décrite dans la référence [ALF]. Notre innovation se situe dans l’adaptation ou customisation d’un algorithme différent de celui utilisé dans [ALF], l’algorithme MOPSO (Multi-objective Particle Swarm Intelligence). En effet, nous avons influencé le comportement standard de l’algorithme, par rapport à celui disponible dans les packages les plus connus (tels que la librairie DEAP écrite en Python). Notre adaptation se situe dans le choix des valeurs des coefficients de confiance, dans le confinement de l’espace de recherche et dans la méthode pour la détermination des solutions « non dominées ».
Par ailleurs, nous souhaitons aller plus loin dans cette dernière avec une customisation de la méthode Є-Dominance.
1.7. Références bibliographiques
1.1.1. Livres blancs (white papers)
[ALF] Alfaro Cid E. et al., « Minimizing value-at-risk in a portfolio optimization problem using a multiobjective genetic algorithm », International Journal of Risk Assessment and Management, 2011
[YOU] Yourdkhani S., « Portfolio Management by using Value-at-Risk (VaR) - A Comparison between Particle Swarm Optimization and Genetic Algorithms », Life Science Journal, 2014
[HAO] Hao J. et al., « Multi-objective Particle Swarm Optimization Algorithm based on Enhanced Є-Dominance », IEEE, 2006
[MOS] Mostaghim S., Teich J., « Strategies for Finding Local Guides in Multi-objective Particle Swarm Optimization (MOPSO) »
[MOS2] Mostaghim S., Teich J., « The rôle of Є-Dominance in Multi-objective Particle Swarm Optimization Methods »
1.1.2. Livres
[CLE] Clerc M., L’optimisation par essaims particulaires, Hermès-Sciences, 2005
[LAR] Larose D., « Exploration de données », Editions Vuibert, 2006
1.1.3. Sites web
1.8. Annexes
1.1.4. Notions de solutions non dominées
Ci-dessous une explication et une illustration de solutions non dominées (carrés noirs).

1.1.5. Théorie de rationalité avancée par Markowitz
Le problème posé par Markowitz est la recherche d’un portefeuille qui minimise la variance du rendement du portefeuille pour un niveau d’espérance de rentabilité donné.
Ce portefeuille est dit efficace, il a l’espérance de rentabilité la plus forte parmi les portefeuilles qui ont la même variance de rentabilité que lui.
Ainsi, le problème de l’investisseur face à plusieurs titre serait de déterminer la proportion de ses fonds à investir dans chaque titre pour former le portefeuille efficient qui correspond au mieux à ses goûts vis-à-vis du risque.
L’ensemble de tous les portefeuilles efficaces constitue la frontière efficace, encore appelée frontière efficiente de Markowitz (Prix Nobel d’économie en 1990), qui la dériva en 1952 et la généralisa en 1959.
Markowitz est classé comme le premier modélisateur de la relation « Risque / Rentabilité ».
Le modèle de Markowitz devient l’outil le plus préconisé par les opérateurs et ce grâce à son opérationnalité et sa technicité.
1.1.6. Les différents types de portefeuille
Portefeuille efficient (efficient portfolio)
Pour chaque rendement, il existe un portefeuille qui minimise le risque. À l'inverse, pour chaque niveau de risque, on peut trouver un portefeuille maximisant le rendement attendu. L'ensemble de ces portefeuilles est appelé frontière efficiente ou frontière de Markowitz.
Portefeuille à variance minimale (Global minimum risk or Minimum Variance Portfolio)
C’est le portefeuille efficient avec le risque minimal.
Portefeuille à rentabilité maximale (Maximum Return Portfolio)
C’est le portefeuille qui pour un risqué donné (cible), possède la rentabilité maximale.
Portefeuille tangent ou de risque minimal (Minumum Risk or Tangency Portfolio)
Dans un univers comprenant des actifs risqués et un actif sans risque, le portefeuille tangent est le seul portefeuille risqué efficient puisqu'il est celui dont le ratio de Sharpe est le plus élevé. C’est le portefeuille efficient avec le ratio rendement/risque (ou ratio de Sharpe) le plus élevé.
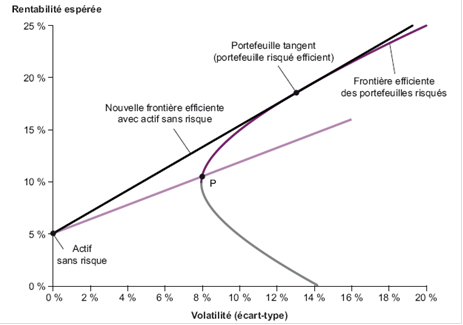
Autres définitions
L'actif sans risque est un actif théorique qui rapporte le taux d'intérêt sans risque. Il est en général associé aux emprunts d'État à court terme. Cet actif possède une variance nulle, son rendement est donc connu à l'avance. Il n'est pas corrélé avec les autres actifs. Par conséquent, associé à un autre actif, il modifie linéairement l'espérance de rendement et la variance.
Le portefeuille devient donc:
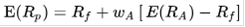
En conséquence, l'espérance de rentabilité est constituée de l'actif sans risque augmenté d'une prime de risque.
Droite de marché des capitaux (Capital Market Line)
Elle représente la rentabilité attendue en ordonné et le risque en abscisse de l'ensemble des titres présents sur le marché. Si un titre se situe au-dessus de cette droite, il est sous-évalué. En effet, cela signifie qu'il rapporte plus que ce qui est attendu à un risque donné, donc investir !
L'intersection avec la droite des ordonnées représente le taux de rentabilité attendu sur les marchés pour un risque nul.







